DailyArt
Discovering Articulation from Single Static Images via Latent Dynamics
Discovering Articulation from Single Static Images via Latent Dynamics

Articulated objects are essential for embodied AI and world models, yet inferring their kinematics from a single closed-state image remains challenging because crucial motion cues are often occluded. Existing methods either require multi-state observations or rely on explicit part priors, retrieval, or other auxiliary inputs that partially expose the structure to be inferred. In this work, we present DailyArt, which formulates articulated joint estimation from a single static image as a synthesis-mediated reasoning problem. Instead of directly regressing joints from a heavily occluded observation, DailyArt first synthesizes a maximally articulated opened state under the same camera view to expose articulation cues, and then estimates the full set of joint parameters from the discrepancy between the observed and synthesized states. Using a set-prediction formulation, DailyArt recovers all joints simultaneously without requiring object-specific templates, multi-view inputs, or explicit part annotations at test time. Taking estimated joints as conditions, the framework further supports part-level novel state synthesis as a downstream capability. Extensive experiments show that DailyArt achieves strong performance in articulated joint estimation and supports part-level novel state synthesis conditioned on joints.
Click to watch! We visualize 3D joints by projecting them back to 2D, and novel states by merging the images into GIFs.
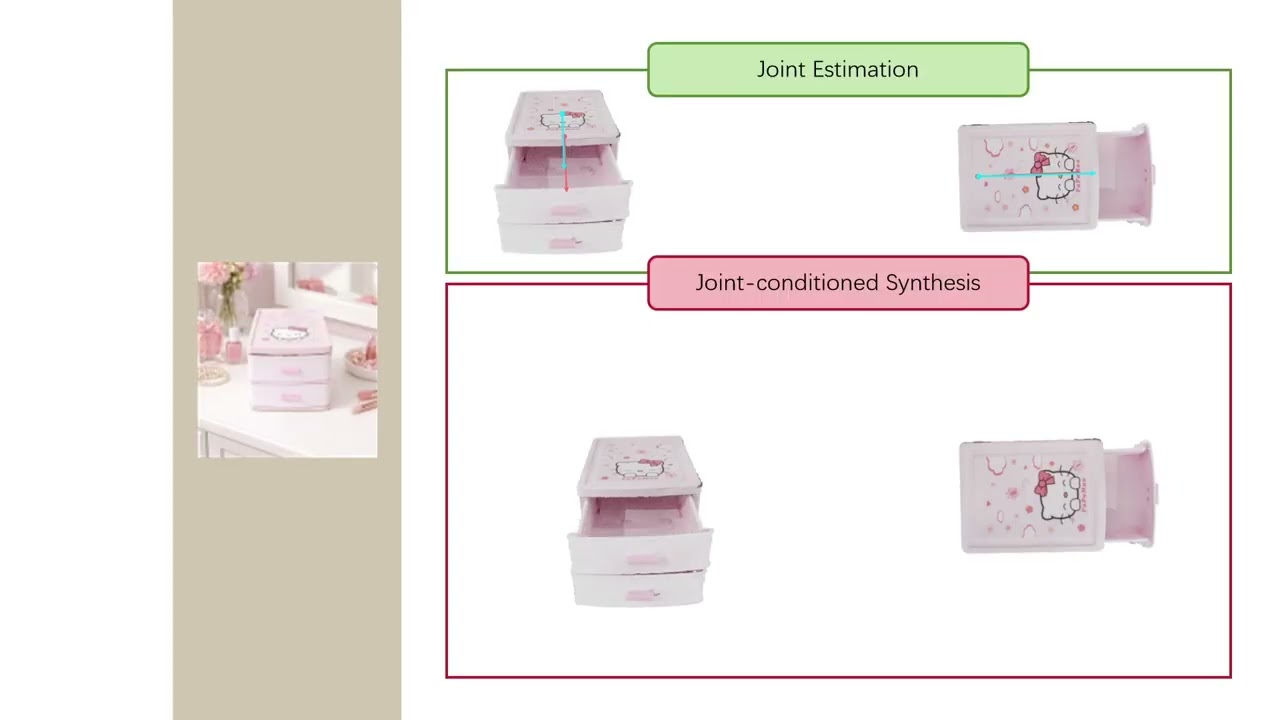
Click an example on the left to preview the result.




The selected feature result will appear here.
Joint Estimation
Novel State Synthesis
@misc{zhang2026dailyartdiscoveringarticulationsingle,
title={DailyArt: Discovering Articulation from Single Static Images via Latent Dynamics},
author={Hang Zhang and Qijian Tian and Jingyu Gong and Daoguo Dong and Xuhong Wang and Yuan Xie and Xin Tan},
year={2026},
eprint={2604.07758},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2604.07758},
}